如何打造 Miva | 第二部分:平衡多代理人系統的協作

如何打造 Miva | 第二部分:在多代理人系統協作與商業現實之間取得平衡
接續第一部分:從系統提示詞到多代理人系統的演進
在先前的討論中,我們探索了 Miva Lite 的基礎架構以及 BookAI 系統提示詞(System Prompt)背後的哲學。本篇將深入探討更複雜的挑戰:我們如何處理超出特定書籍內容的讀者詢問?跨多個 AI 代理人(Agents)的有效協作是什麼樣子的?最重要的是,我們如何在技術抱負與商業實務需求之間取得平衡?
▎當書中沒有答案時(而讀者並不知情):「邊界問題」的解決方案
在現實場景中,讀者經常提出自然延伸到「書籍邊界之外」的問題。一個典型的例子是讀者誤解了書名,認為他們正在閱讀卡內基的原著,但實際上那是重新詮釋的作品。由於 Miva 提供的是摘要而非直接存取原著全文,我們開發了兩個主要的解決方案:主動理解並精煉讀者的意圖,以及透過精心設計的體驗流程來管理使用者預期。
我們主動理解並精煉問題的技術解決方案涉及一個專門的代理人:意圖釐清代理人(Intent Clarification Agent)。它的任務很明確:真正掌握讀者想知道什麼。它處理讀者的輸入,識別其核心意圖,然後增強並重新建構原始問題,增加細節、進行分類,並為後續的代理人做好準備。
<Intent_Clarification_Agent_Core>
- 首要任務:了解讀者「真正」想知道什麼
- 防止答案生成代理人的認知負荷過重
- 處理模糊、簡短或誤導性的查詢
- 彌合使用者意圖與書籍內容邊界之間的差距
</Intent_Clarification_Agent_Core>此代理人充當預過濾器,在主要回答代理人接手之前分析簡短的關鍵字或概念。這種「預處理」機制讓回答代理人能更精確地理解問題範圍,顯著降低產生無關或錯誤回應的可能性。
LLM 即 UX:利用 LLM 進行預期管理,並引導讀者「感知書籍資訊邊界」
「LLM 即 UX」是 BookAI 團隊的一項指導原則:利用 LLM 來增強使用者體驗,無論是透過動態生成的 UI 還是直接的文字引導。這促使我們設計了一套策略,幫助讀者「感知書籍的邊界」。以下是 Miva Pro 中採用的指令:
Miva Pro 的處理方法:
<Handling_Insufficient_Excerpts_By_Tier>
- 當書籍摘錄(book_excerpts)不足時,提供你能提供的內容並說明限制。
- 關鍵:你「必須」使用如下短語進行清晰的轉折:
「根據摘錄 [1],我可以解釋 [面向 A]。然而,這並未涵蓋 [主題 B] 的全部內容。
為了提供完整的全貌,我將補充我自己的知識……」
- 關鍵:你「必須」清晰地標註免責聲明:
[!! 註:以下細節超出了我找到的書籍摘錄範圍 !!]
</Handling_Insufficient_Excerpts_By_Tier>這些指令優先考慮忠實呈現書籍內容。同時,Miva 被賦予權限,可以清楚地指出書籍資訊的限制,並在適當時提供有價值的補充知識。
▎付費牆:釋放創造力的分層方法
AI 系統的變現一直是一項具挑戰性的任務。
當考慮像「書籍摘要」這樣看似簡單的服務時,我們如何區分價值並提供讓使用者付費的說服力理由?我們的方法是從服務業的角度來看待這個問題。
服務業銷售的是「服務」本身,從第一次互動就產生價值,儘管不一定立即收費。就像咖啡店提供試喝或健身房提供體驗課一樣,許多服務都從較輕量的體驗開始。一旦客戶的需求達到一定程度,付費意願自然會隨之而來。應用這個邏輯,我們構思了一個具有不同強度的分層「付費書籍摘要服務」。
這個過程涉及許多可調整的參數:回答的深度、分析的廣度、創意延伸的程度,以及跨多本書進行比較的能力。然而,在控制 LLM 的技術方面,我們發現限制 LLM 固有的創造力提供了一個極佳的切入點。
在我們的服務設計中,「是否允許 LLM 提供書籍內容以外的資訊」一直是一個重大的哲學與技術難題。一方面,我們希望 LLM 嚴謹求實——「有的就有,沒有就沒有」——完全忠於原著,儘管這可能導致服務變得相當枯燥。另一方面,我們希望 LLM 能提供相關的補充資訊和延伸,因為我們承認所有書籍都有知識邊界,而讀者的好奇心經常超越這些限制。
因此,定義「創意任務」變得至關重要。我們需要與「讀者」和「書籍提供者」建立明確的共識:在什麼特定情況下,我們會釋放 LLM 的創作能力?這正是實施訂閱分層機制的契機。
實施分層的「書籍摘要服務強度」
我們設計了以下分層邏輯:免費服務專注於介紹已知內容,類似於書店店員的基本推薦。付費服務在面對創意任務時,可以適度擴展其生成能力,就像私人閱讀顧問可能提供的深度分析。Miva Lite(免費版)嚴格專注於書籍內容,不執行任何創意工作:
<Creative_Task_Handling_By_Tier>
- 創意任務超出 Miva Lite 的範圍。
- 範例:「Miva Lite 簡要介紹書籍。
對於創意探索,Miva Pro 提供更多功能。」
</Creative_Task_Handling_By_Tier>Miva Pro(付費版)被允許在找到書籍內容的基礎上擴展想像力並生成輸出:
<Creative_Task_Handling_By_Tier>
- 你擅長處理創意任務。
- 「創意任務」定義:任何要求生成新的、結構化的成品大綱的請求
- 利用書籍摘錄(book_excerpts)和你的知識來創作詳細且具洞察力的內容。
</Creative_Task_Handling_By_Tier>這種差異化服務設計的底層哲學很簡單:只有付費使用者才能受益於 LLM 的完整創意潛力。
免費使用者會收到簡潔、保守但可靠的書籍介紹,主要用於探索。然而,付費使用者則享有更豐富的創意延伸和更深層的分析洞察。透過策略性地利用技術限制,我們精心打造了一個刻意的商業模式。
我們投入了大量時間建立一份清晰的「創意任務參考表」,細緻地定義了在各種情況下允許的創意自由度。例如,允許基於書籍內容的概念延伸,跨書比較分析則是付費功能。然而,嚴禁創造書中沒有的觀點或做出超出作者論點的推論。
▎多代理人系統:協作挑戰與優化
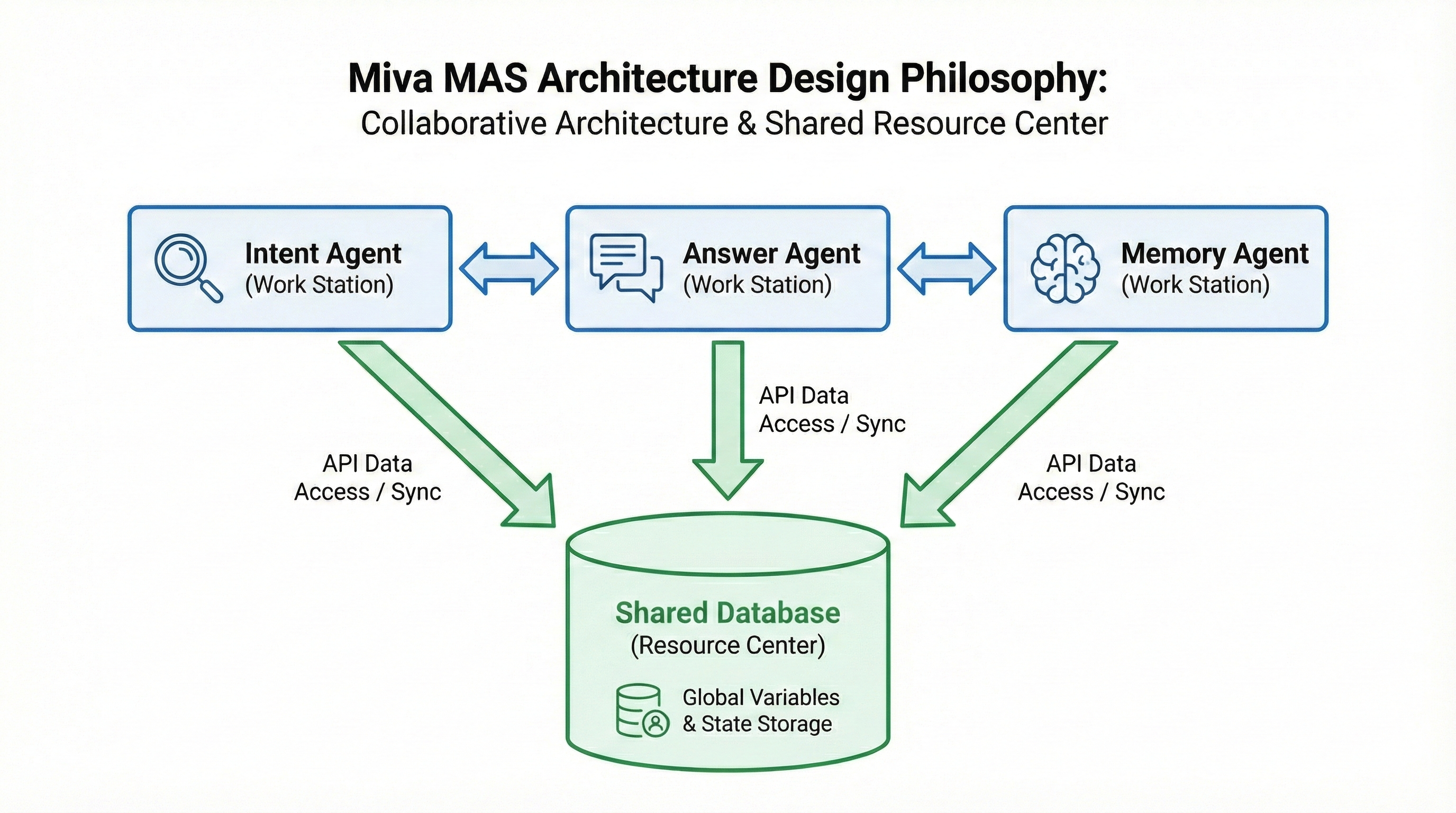
我們的多代理人系統(MAS)架構已逐步演進,從 2024 年第二季的 2 個代理人增加到第四季的 4 個。每次擴展都引入了新的複雜性。MAS 設計中最具挑戰性的部分不是單個代理人的開發,而是跨代理人的全域變數定義。擴展此類架構主要涉及管理多個獨立代理人如何有效溝通並存取共享資料庫,從而降低未來的維護複雜性。我們的解決方案是以 API 為導向的複合架構設計:
Miva MAS 架構設計哲學
在這裡,每個代理人都像一個「獨立工作站」一樣運作,透過一個充當中央資源樞紐的共享資料庫連結。這種設計哲學直接從豐田生產系統(Toyota Production System)的工作站專業化概念中汲取靈感。
從豐田生產線管理到代理人工作流管理:現代營運管理的實踐
在處理複雜的多代理人系統時,我們意外地發現製造業營運管理為解決方案提供了一個極佳的框架。每個代理人都鏡射了生產線上的一個專業工作站,具有定義明確的輸入、處理步驟和輸出標準。
工作站專業化的核心原則規定,不應由一個全能的代理人處理所有任務,而應讓每個代理人專精於特定功能。意圖釐清代理人專注於理解使用者意圖,答案生成代理人專注於撰寫回應,而記憶管理代理人則負責監督對話記憶。這種分工讓每個工作站都能達到最佳效能,並有利於獨立改進。
模組化設計理論將複雜系統分解為可以獨立開發和替換的標準化模組。我們將此應用於管理我們的系統提示詞(System Prompts)和指令(Instructions)。就像製造業中的標準化零件一樣,每個指令模組都有明確的定義,允許獨立開發、測試和替換。如果某個代理人需要調整,我們只需修改其對應的模組,而不會損害整個系統的穩定性。
系統的整體效能通常受限於其最薄弱的環節。限制理論(TOC)強調專注於 MAS 的瓶頸以實現有效的改進。監控每個代理人的延遲(latency)類似於追蹤生產線上每個工作站的週期時間和品質。這使得在每個階段都能進行有針對性的增強:調整提示詞、切換 LLM 或更改工作流,同時針對不同的任務需求優化設備配置。正如工作站可以配備不同的機器規格一樣,需要精確理解的代理人可能會使用更強大的模型,而處理簡單任務的代理人則可以使用更具成本效益的模型。透過這種專用設備的概念,我們在效能、成本、效率和客戶滿意度之間取得平衡。
營運管理最關鍵的面向是建立穩健的評估指標,例如 六標準差(Six Sigma)DMAIC 流程改進方法。這個由數據驅動的五步驟循環(定義、測量、分析、改進、控制)用於增強、優化和穩定業務流程與設計。透過將前端的 GTM 數據與後端的語義分析相結合,我們建立了一個持續改進機制。這涉及對去識別化數據進行深入分析,以構建品質評估矩陣,主要評估情境理解、每個流程環節的品質與穩定性,以及最關鍵的——傾聽客戶的聲音(VOC)。
採用營運管理思維的最大價值在於我們管理和評估複雜代理人工作流(Agentic Flows)的系統化方法。這不是由直覺或試錯驅動的,而是由理論和分析支持每一次改進,確保每次調整的影響都能得到量化評估。
▎尊重原創的 AI 產品哲學:及時驗證商業模式
雖然「準確引用原著」聽起來至關重要,但大多數使用者並不主動關心我們是否引用了某本書的特定段落。對讀者來說真正重要的是他們的問題是否能得到有效解決。我們的核心哲學規定,賦予讀者輕鬆購買書籍的能力,是對作者和出版社最真實的尊重表現。
我們的案例研究從 Google 圖書的經驗中汲取靈感。最初,提供全文檢索的免費服務 Google 圖書搜尋被認為間接侵犯了版權和出版權,導致美國出版商協會和作者協會提起訴訟。和解的關鍵時刻出現在 Google 調整策略時,僅顯示部分搜尋片段並包含購買連結。這教會了我們「消費是對原創最直接的支持」。在 AI 書籍摘要服務中,僅提供技術並不能保證可行的商業模式;核心在於在尊重版權的同時提供服務,並自然地引導讀者進行消費。
從那時起,UX 設計和潛在客戶開發(lead generation)一直是我們對作者的重要承諾。這確保了使用者在直覺上表現出對原創內容尊重的同時,也符合我們作為知識資產提供者的商業定位。
自從古騰堡印刷機發明以來,出版業已成熟為一個傳統的、以版權為核心的產業。引入先進的 AI 技術並建立全新的商業模式是一項重大挑戰。對於一個深切關注版權的產業來說,贏得作者和出版社的信任比單純的技術實力更具挑戰性。我們的策略是:首先,構建一個清晰、具體的商業模式概念驗證(POC),以確定市場、作者和出版社所感知的真實價值。
在這裡,商業模式的精實驗證是我們的指導營運原則。在評估技術可行性後,我們採用了以「提案構思」為中心的溝通策略,主動與各方利害關係人進行對話。這種互動方式讓我們能深入了解他們的真實需求、潛在擔憂和未表達的期望。通常,具體的提案能有效激發更深層的討論,幫助雙方共同定義合作邊界和潛在發展方向。
隨著商業模式預先得到驗證,技術實作和架構設計可以更務實地達成與平衡:
功能優先級排序:識別對商業模式真正關鍵、必須優先實作的功能。
迭代式使用者體驗改進:根據真實回饋逐步增強使用者體驗,而不是從一開始就追求完美的解決方案。
▎與書籍和語言的在地對齊:矽谷 LLM 的在地化挑戰
在開發過程中,我們最大的技術障礙是矽谷公司訓練的 LLM 在處理「在地語言」時通常表現不佳。秉持「不使用書籍內容訓練 AI」的承諾,我們開發了 BookAI Operator Legend 系統,利用情境學習(In-Context Learning)。該系統利用 LLM 的模式識別能力來強制執行嚴格的語言控制機制:
<taiwanese_mandarin_usage_rules>
§§§ !!!:"資料品質"~:="Data Quality";
"專案"~:="Project";"項目"~:="Item";"列"~:="Row";
"行|欄"~:="OPTIONS=Column";"程式碼"~:="Code" §§§
</taiwanese_mandarin_usage_rules>BookAI Operator Legend 系統具有多項優勢。從技術上講,它不需要額外的模型訓練或微調。透過採用專門設計的符號組合,該系統巧妙地利用了 Transformer 模型的內部注意力機制,使 LLM 能夠學習高度受控的語言輸出規則。
此外,考慮到現代 LLM 上下文視窗的不斷擴大和採樣能力的持續提升,BookAI Operator Legend 系統在實際應用中展現了卓越的靈活性。這意味著我們可以隨時擴展和更新必要的在地化語言映射表,以滿足不斷演變的應用場景。
在我們的設計哲學中,使 AI 服務與在地書籍內容和在地語言慣例對齊,並努力盡可能忠於作者的原始觀點,是一項極具挑戰性但至關重要的任務。這種專為動態在地語言對齊而設計的少樣本情境學習(few-shot in-context learning)方法已在我們的 Miva 應用程式中全面實施。我們希望這能促使出版業和其他企業深入思考整合我們 API 產品的潛力:書籍是受保護的知識資產,未來任何「受保護的高價值知識資產」都將納入我們的服務範圍。
Miva 只是 BookAI 團隊的一個完整應用型產品。我們還提供面向企業的 API 產品,如 Coeus、Heka 和 Osmi,它們都建立在相同的核心技術架構之上。透過嚴謹的系統架構、精確的提示詞工程(Prompt engineering)和深厚的人文關懷,我們渴望成為知識市場的長期合作夥伴,擅長將靜態文件和書籍轉化為動態的、具市場價值的知識服務。
▎在快速演進的 AI 浪潮中保持初心
從最初的兩個代理人到現在完整的多代理人系統架構,從簡單的書籍問答到複雜的知識服務,Miva 的開發歷程凸顯了我們的核心問題:AI 技術如何能真正服務於知識的傳播?沒有單一的答案;它需要人文關懷、商業成功、技術創新和社會責任之間找到動態的、雙贏的平衡。
對我們來說,建立一個清晰的框架作為起點已被證明是無價的。透過以人文服務為中心,持續關注每一位利害關係人的利益,並利用 AI 技術達成平衡,我們守住了我們的指導原則。
你認為 AI 書籍摘要工具最關鍵的能力是什麼?是忠實傳達原著精神,還是提供個人化的見解與延伸?
下一篇將進一步深入探討開發過程中的實際案例研究和「幕後挑戰」,探索使用者行為分析如何引導產品優化,並分享我們對 AI 閱讀服務未來的最終願景。
(第二部分完)


